

Google has been allowed to scan hundreds of thousands of out-of-copyright books from libraries around the world and supposedly this is a wonderful free resource for all of us. But, over the last year or two, I’ve found it increasingly difficult to find the free versions while Google Books presents reprints to buy.
Here’s an example…
“Reminiscences of Manchester fifty years ago” was written by J.T.Slugg and published in 1881. According to a review of the book in The Manchester Guardian on 6 April 1881 “Mr. Slugg came to Manchester as a mere lad in 1829”. So it’s certainly more than 70 years since he died, meaning that this book is out of copyright.
And here it is at archive.org.
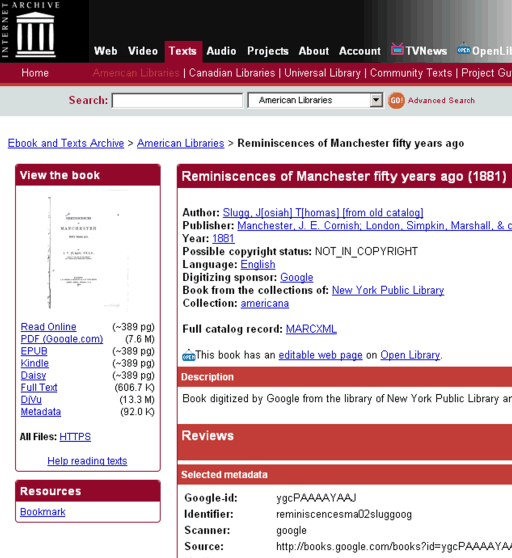
I can view it there in various forms, but I don’t want text or to read online. I would like to download the pages of the book as originally published. However, if I click on the link “PDF (Google.com)”, oh dear, I see this:
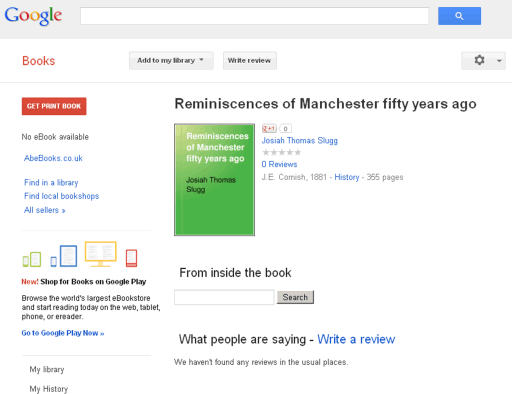
No eBook is available apparently. If I click the link to AbeBooks.co.uk there are numerous secondhand hard copies that I can buy and there are other links in the lefthand column to people selling. At the bottom of the screen it tells me:
Bibliographic information
Title Reminiscences of Manchester fifty years ago
Author Josiah Thomas Slugg
Edition reprint
But I don’t want a reprint and I don’t want to buy. I want a free PDF scan of the out of copyright original please.
Google has been doing this for a while. In the past I would click on the cog symbol at the top right, select Advanced Book Search and I would search for the title and possibly author and would find various versions of the book.
So let’s try that. Into the Exact Phrase box I type “Reminiscences of Manchester” and into With At Least One of the Words box I type Slugg, I tick Full View Only. But darn it, the result is one link back to exactly the same page on archive.org.
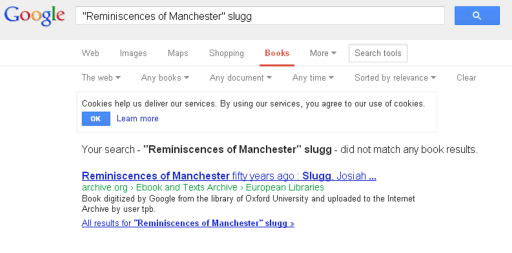
I try putting just J.T.Slugg into the With the Exact Phrase box. That finds various articles but not the book. I try “Slugg, Josiah Thomas” and “Josiah Thomas Slugg” but still no free PDF.
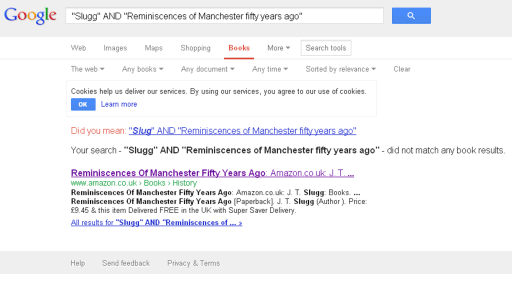
I try “Slugg” AND “Reminiscences of Manchester fifty years ago”. Google tells me:
Your search – “Slugg” AND “Reminiscences of Manchester fifty years ago” – did not match any book results.
Really? But oh how helpful, Google HAS found a link to a copy I can buy on Amazon for £9.45.
In fact, if I look hard enough on archive.org by clicking “All Files: HTTPS” in the left hand column (how many people do that?), there’s a direct link to a free PDF hosted by them. The first page makes clear it was scanned by Google.
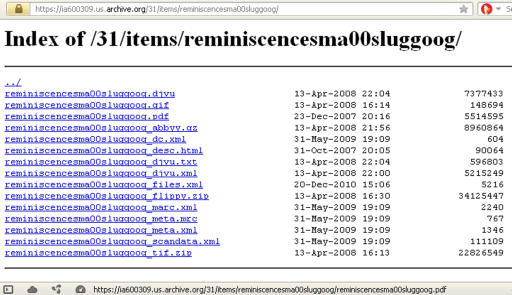
Why does the main PDF link at archive.org go to Google?
This isn’t a one off. I had the same problem with Google Books a few weeks ago when I tried to find a copy of Rural Rides by William Cobbett which was published in 1832.
In fact these are exactly the kind of timewasting games that the worst porn websites have always played: sending people around in circles until, out of frustration, they click and buy something.
The difference is that Google has been given access to vast quantities of books from libraries that were funded by the public.
And apparently now it’s using that out of copyright content to pull people in and send them to commercial sellers while, at the same time, doing everything it can to hide free versions which it has scanned and probably are hosted somewhere on its own servers.
I suspect that when Google was allowed to do this scanning it was agreed that it was only on the basis that the scans would be freely available to the public?
It’s interesting to compare these dirty tricks to the changes that were introduced to Google Images last January. Many webmasters have seen a 60% drop in traffic from that source since then.
That’s because the new layout on Google Images gives visitors less reason to click through to the site that hosts the full-size image (and which in many cases put in the effort to create that content in the first place).
What Google Images does is known as hotlinking. Traditionally something which has always been frowned on because it’s rather underhand and little more than theft of server resources and content.
It’s time for the various regulators around the world to crack down on Google before all of this goes any further.
3 Comments
The reason this book is being blocked is because you are trying to access it from outside the United States. Users within the USA can freely access it.
Within the USA, all digitized books that were published before 1923 are in the public domain. Google makes all of these books freely accessible to American users.
In the UK and E.U., copyright lasts for 70 years after the death of an author. In these countries, accurate biographical information about each author is needed to assess whether a particular book is in the public domain.
Unfortunately, Google does not use biographical data to assess the copyright status of each book. Instead it makes a crude estimate of copyright status, blocking all of its books for 140 years after publication (i.e. all books published after 1873). “Reminiscences of Manchester fifty years ago” was published in 1881, so has been blocked by Google’s estimation process.
I assume that an American must have downloaded a copy from Google Books, and then uploaded it to the Internet Archive. The reason it is still available on the Internet Archive is because they make all of their content available globally on the same terms as American users.
I’m about to publish a paper about this issue, feel free to have a look at my initial draft:
http://www.kiwialex.com/1/post/2013/03/about-the-project.html
Wow, man, you are very generous by posting this information, which by the way was REALLY DIFFICULT to find. Although the information was here already (http://archive.org/post/930217/why-does-the-main-pdf-link-go-to-google-books) it was not clear enough, but you made it straightforward.
Thank you.
Just found this while trying to understand the same issue. Very helpful thanks. Unfortunately, the link to Alex’s paper is broken.